

Introduction to the Intel® Distribution of OpenVINO™ toolkit with the Intel® RealSense™ Viewer
In today’s software ecosystem, everyone seems to be leveraging some form of Artificial Intelligence (AI, also commonly referred to as Machine Learning) to perform analysis that was not traditionally performed well by a computer. More traditional software paradigms lack the capacity to properly describe complex interactions between a variety of different inputs.
One usage of AI in particular is in the field of human vision, or the approximation of human-like vision. Object recognition and inference can be used in many ways to enable new and exciting capabilities. A hospital computer can diagnose breast cancer with high accuracy, by replacing previous high cost human labor with specially trained software. A drone can navigate and orient itself based on classification of objects (person, car, building, etc.) from visual inputs, or fly along electricity lines identifying problems like overhanging vegetation. The store you just walked out of could track the items you chose and charge you accordingly, without the need to check out. Your computer at home could identify your mood and play an appropriate soundtrack. AI imitates the way our brains work by setting up and training neural networks for specific tasks, similar to how we might practice a new skill by repeating it over and over.
The Intel® Distribution of OpenVINO™ toolkit, or “Open Visual Inference and Neural network Optimization” and, as its name suggests, is an optimized convolutional neural network (CNN) implementation designed to run on Intel hardware (CPU, GPU, or some other accelerator). It can leverage custom optimizations that provide added scalability and directly translate to increased throughput and performance. When your model incurs a heavy workload, every additional frame per second counts, and that’s where the OpenVINO™ toolkit shines.
The OpenVINO™ toolkit and Intel® RealSense™ Technology
AI works on models that are trained on specific data. The more data, and more varied the data, the better the accuracy of the resulting model. Today, visual models are typically trained on a set of images that contain the appropriate subject matter: faces if you want to train facial features, etc. However, all these images are typically two-dimensional without any depth information to give additional cues. Like a brain working with two dimensions instead of three, depth needs to be inferred or even assumed in order to make any further determinations. How can you differentiate between a person and a picture of a person?
Intel® RealSense™ cameras and technologies are particularly well suited to enable a third dimension of input into AI models, enabling capabilities that did not exist before. The OpenVINO™ toolkit supplies inference that is optimized and enables more complex models that provide more accurate results in realtime, Intel® RealSense™ products provide the necessary information needed to actually make decisions, and without which such decisions are mere approximations. The two are complementary and both are critical to providing a good experience.
The Viewer
Intel® RealSense™ SDK’s Viewer has long been one of the best demonstrations of the technology, able to immediately make clear its added value. We wanted to introduce the OpenVINO™ toolkit into the Viewer as a vehicle for future functionality and a way of showcasing some of its capabilities at the same time.
The end-result is a post-processing engine that can take the RGB frames from the Intel® RealSense™ camera, run them through the Intel® Distribution of OpenVINO™ toolkit and show faces, with gender and age, for the people it detects:

Intel RealSense Viewer with the OpenVINO toolkit at IROS 2019, Macau
The addition to the viewer is a simple post-processing block for RGB frames that can be turned on or off at will, as seen in the screenshot below.
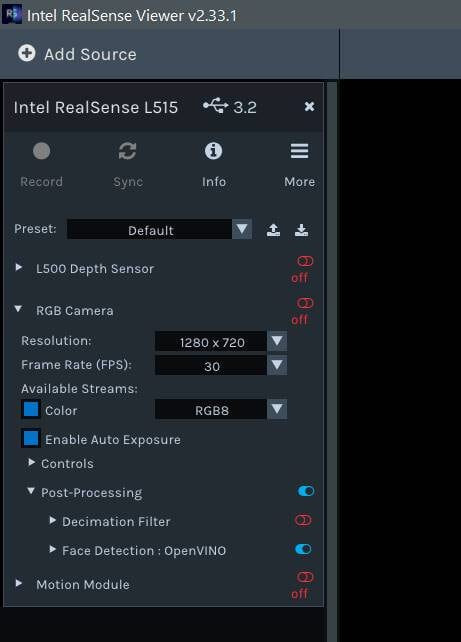
This post-processing block does the following:
- Load two models into an inference engine instance running on the CPU: face detection and age/gender detection
- For each RGB frame:
- Detect faces (bounding boxes)
- For each face:
- Figure out if it was seen in the previous frame, using some color & depth heuristics
- If new, ask the OpenVINO toolkit to estimate gender and age
- Remove old faces
Note that the depth information here is used for estimating average distance to the face in question, and not as part of the model detecting the face. Pixels within the bounding box that do not fit into the expected dimensions of a head (a wall in the background, for example) do not get counted, allowing for better segmentation of the data.
Age and gender estimation can be done for each and every frame, with the results aggregated into a running estimate rather than taking just the first frame into account (which may cause some error). It is recommended to check out some of the examples in the Intel Distribution of OpenVINO toolkit for further examples, as well as for other actions that can be easily performed once a face has been detected: feature extraction (jawline, eyes, nose), emotion, orientation, etc.
For this version of the viewer, additional dependencies exist (the models, the Intel® Distribution of OpenVINO™ toolkit, etc.) so note that the OpenVINO™ toolkit functionality is only available from the Windows installer or by building the SDK yourself.
To see more, check out the code and the other examples, or contribute, check out the SDK at: https://github.com/intelrealsense/librealsense. In particular, two OpenVINO™ toolkit examples exist in the SDK:

Faces being detected by the Intel RealSense Viewer with the OpenVINO toolkit
OpenVINO and the OpenVINO logo are trademarks of Intel Corporation or its subsidiaries.
Subscribe here to get blog and news updates.
You may also be interested in
“Intel RealSense acts as the eyes of the system, feeding real-world data to the AI brain that powers the MR
In a three-dimensional world, we still spend much of our time creating and consuming two-dimensional content. Most of the screens